
Chapter 15: HTML to PDF Conversion
Contents
15.1 ImportFromUrl Method
AspPDF.NET is capable of converting HTML documents to PDF via PdfDocument's ImportFromUrl method. This method opens an HTML document from a given URL, splits it into pages and renders it onto an empty or existing PDF document. The document can then be further edited, if necessary, and saved to disk, memory or an HTTP stream as usual.
ImportFromUrl's support for various HTML tags and constructs is not quite as extensive as that of major browsers, but still considerably stronger than the limited HTML functionality of Canvas.DrawText available in older version of AspPDF.NET. ImportFromUrl recognizes tables, images, lists, cascading style sheets, etc.
ImportFromUrl accepts four parameters, all but the first one optional: the input URL, a parameter list, and a username/password pair.
The URL parameter can be an HTTP or HTTPS address, such as http://www.server.com/path/file.html, or a local physical path such as c:\path\file.html. Note that if you want to open a dynamically generated document such as an .asp or aspx file, you need to invoke it via HTTP even if this file is local to your own script.
You can also specify an HTML string directly via the URL parameter. This is described in Section 15.5 of this chapter.
The following simple code snippet creates a PDF document out of the Persits Software site persits.com:
PdfDocument objDoc = objPdf.CreateDocument();
objDoc.ImportFromUrl( "http://www.persits.com/old/index.html", "scale=0.6; hyperlinks=true; drawbackground=true" );
string strFilename = objDoc.Save( Server.MapPath("importfromurl.pdf"), false );
Dim objDoc As PdfDocument = objPdf.CreateDocument()
objDoc.ImportFromUrl( "http://www.persits.com/old/index.html", "scale=0.6; hyperlinks=true; drawbackground=true" )
Dim strFilename As string = objDoc.Save( Server.MapPath("importfromurl.pdf"), false )
Click on the links below to run this code sample:

The ImportFromUrl method's 2nd argument is a PdfParam object or parameter string specifying additional parameters controlling the HTML to PDF conversion process. For example, to create a document in a landscape orientation, the Landscape parameter must be set to true, for example:
When new pages have to be added to the document during the conversion process, the default page size is U.S. Letter. This can be changed via the PageWidth and PageHeight parameters.
When rendering HTML content on a page, AspPDF.NET leaves 0.75" margins around the content area. That can be changed via the LeftMargin, RightMargin, TopMargin and BottomMargin parameters.
The full list of ImportFromUrl parameters can be found here.

Under .NET Core on Linux, you must explicitly load all TrueType fonts used by your HTML document (including their bold, italic, and bold/italic versions) via the method objDoc.Fonts.LoadFromFile before calling ImportFromUrl. This is because AspPDF.NET does not know where to find TrueType fonts on Linux. You must load at least one font, Times New Roman, as it is the default font. For example:
PdfFont objFont1 = objDoc.Fonts.LoadFromFile("fonts/times.ttf");
PdfFont objFont2 = objDoc.Fonts.LoadFromFile("fonts/timesbd.ttf");
PdfFont objFont3 = objDoc.Fonts.LoadFromFile("fonts/timesi.ttf");
PdfFont objFont4 = objDoc.Fonts.LoadFromFile("fonts/timesbi.ttf");
...
objDoc.ImportFromUrl(...);
15.2 Authentication
15.2.1 Basic Authentication
The 3rd and 4th arguments of the ImportFromUrl method are a username and password that can be used if the URL being opened is protected via Basic Authentication, as follows:
15.2.2 .NET Forms Authentication
Under .NET, the Username and Password arguments can instead be used to pass an authentication cookie in case both the script calling ImportFromUrl and a file being converted to PDF are protected by the same user account under .NET Forms authentication. To pass a cookie to ImportFromUrl, the cookie name prepended with the prefix "Cookie:" is passed via the Username argument, and the cookie value via the Password argument. The following example illustrates this technique.
Suppose you need to implement a "Click here for a PDF version of this page" feature in a .NET-based web application. The application is protected with .NET Forms Authentication:
<forms name="MyAuthForm" loginUrl="login.aspx" protection="All">
<credentials passwordFormat = "SHA1">
<user name="JSmith" password="13A23E365BFDBA30F788956BC2B8083ADB746CA3"/>
... other users
</credentials>
</forms>
</authentication>
The page that needs to be converted to PDF, say report.aspx, contains the button "Download PDF version of this report" that invokes another script, say convert.aspx, which calls AspPDF.NET's ImportFromUrl. Both scripts reside in the same directory under the same protection.
If convert.aspx simply calls objDoc.ImportFromUrl( "http://localhost/dir/report.aspx", ... ), the page that ends up being converted will be login.aspx and not report.aspx, because AspPDF.NET itself has not been authenticated against the user database and naturally will be forwarded to the login screen.
To solve this problem, we just need to pass the authentication cookie whose name is MyAuthForm (the same as the form name) to ImportFromUrl. The following code (placed in convert.aspx) does the job:
{
PdfManager objPDF = new PdfManager();
string strCookieName = "", strCookieValue = "";
' Search for our authentication cookie
for( int i = 0; i < Request.Cookies.Count; i++ )
{
if( Request.Cookies[i].Name == "MyAuthForm" )
{
strCookieName = Request.Cookies[i].Name;
strCookieValue = Request.Cookies[i].Value;
break;
}
}
PdfDocument objDoc = objPDF.CreateDocument();
objDoc.ImportFromUrl( "http://localhost/dir/report.aspx", null,
"Cookie:" + strCookieName, strCookieValue );
objDoc.SaveHttp( "attachment;filename=report.pdf" );
}
Dim objPDF As PdfManager = new PdfManager()
Dim strCookieName As String = "", strCookieValue = ""
' Search for our authentication cookie
For i As Integer = 0 to Request.Cookies.Count - 1
If Request.Cookies(i).Name = "MyAuthForm" Then
strCookieName = Request.Cookies(i).Name
strCookieValue = Request.Cookies(i).Value
Exit For
End If
Next
Dim objDoc As PdfDocument = objPDF.CreateDocument()
objDoc.ImportFromUrl( "http://localhost/dir/report.aspx", Nothing, _
"Cookie:" + strCookieName, strCookieValue )
objDoc.SaveHttp( "attachment;filename=report.pdf" )
End Sub
Note that the cookie name is prepended with the prefix "Cookie:" before being passed to ImportFromUrl.
15.3 Error Log
ImportFromUrl throws an exception if the specified URL cannot be found or invalid, and no HTML to PDF conversion takes place. However, if the main URL is valid but some of the dependent information (fonts, image URLs, CSS files, etc.) cannot be found, the conversion will go on uninterrupted, although the resultant PDF document may not look as expected.
To simplify debugging, ImportFromUrl can be used in a debug mode. If the parameter Debug=true is used, ImportFromUrl returns a log of non-fatal errors encountered during the conversion process. A log entry consists of the entry type, such as "Image", "CSS", etc., error message, and relevant data, such as the invalid URL, unknown font name, etc. Log entries are separated by two pairs of CR/LF characters.
The following code snippet invokes ImportFromUrl in the debug mode and displays the error log:
Response.Write( strLog );
A typical log string may look as follows:
Data: http://www.persits.com/image.gif
Font: Font name cannot be found.
Data: Arrial
15.4 Page Breaks
HTML allows page breaks for printing purposes via the CSS properties page-break-before and page-break-after. The ImportFromUrl method recognizes these properties for the purpose of page breaking in a limited set of HTML tags. The value for these two properties must be set to "always", other values will have no effect. Just like with any CSS property, inline syntax or a separate style sheet can be used. For example:
The property page-break-before: always can be applied to the following tags:
<IMG>
<HR>
<TABLE>
<DIV>
The property page-break-after: always can be applied to the following tags:
<IMG>
<HR>
15.5 Direct HTML Feed
Starting with Service Release 1.6.0.8, the ImportFromUrl method allows you to specify an HTML string directly via the first parameter (URL). The string must contain the sub-string <HTML or <html to be recognized as a direct HTML feed and not a URL. For example:
objDoc.ImportFromUrl( str );
If an HTML string is to include references to images, or other external objects, you must use fully qualified URLs for these objects. Fractional URLs will not be recognized since there is no "base" URL to be applied here:
' Correct
string str = "<HTML><IMG SRC=\"c:\path\logo.jpg\"></HTML>";
' Incorrect
string str = "<HTML><IMG SRC=\"images/logo.jpg\"></HTML>";
15.6 CSS Media Selection
The ImportFromUrl method can be configured to choose which cascading style sheets to read and which to ignore depending on the MEDIA attribute of the <STYLE> and <LINK> tags.
ImportFromUrl recognizes the following values for the MEDIA attribute:
"ALL"
"SCREEN"
"PRINT"
"ASPPDF"
The first three are part of the CSS specs, and the last one is a special value which enables you to create a style sheet specifically for AspPDF.NET.
Using the Media parameter, you can specify a combination (sum) of the following values:
For example, the following call makes ImportFromUrl read only the style sheets with the MEDIA attribute set to "ALL" and "ASPPDF" (and also those without a MEDIA attribute):
By default, the Media parameter is set to 255 which means ImportFromUrl ignores the MEDIA attribute altogether and loads all the style sheets it encounters.
15.7 Obtaining X- and Y-Boundaries
As of Version 1.9, you can retrieve the (estimated) Y-coordinate of the lowest boundary of the HTML content rendered by the last successful call to ImportFromUrl, and also the index of the page within the document where the rendering ends.
This information is obtained via a new PdfDocument property, ImportInfo, which returns an instance of the PdfParam object populated with two items, "Y" and "Page", which correspond to the Y-coordinate and page index, respectively.
The following snippet performs some HTML-to-PDF conversion and then draws a horizontal line right underneath the HTML content on the page where the rendering ends:
PdfParam objParam = objDoc.ImportInfo;
int nIndex = objParam["Page"];
float fY = objParam["Y"];
PdfPage objPage = objDoc.Pages[nIndex];
objPage.Canvas.DrawLine( 0, fY, objPage.Width, fY );
As of Version 3.4.0.33257, the PdfParam object returned by ImportInfo also contains an estimated right-most boundary of the content stored in the "X" item. It can be retrieved the same way as the Y item:
float fX = objParam["X"];
15.8 Templates
As of Version 3.2, a PdfDocument object may be assigned one or more PdfGraphics objects to be used as templates automatically every time a new page is added to the document. This feature should be used in conjunction with the ImportFromUrl method when HTML rendering needs to be performed on top of templates as opposed to blank pages.
One or more PdfGraphics objects can be designated as templates for a particular PdfDocument object by calling the method PdfDocument.AddTemplate. This method takes two arguments: an instance of the PdfGraphics object to be used as a template, and an optional list of parameters specifying which pages (by index) this template should be applied to, as well as the template's position and scaling on the pages.
The From and To parameters specify a 1-based range of page indices that this template is applicable to. By default, From is 1 and To is infinity. To specify multiple ranges, the pairs From1/To1, From2/To2, etc. should be used. Odd and even pages can be excluded from the selected ranges if the parameter Exclude is set to 1 and 2, respectively. If this parameter is set to any other number or omitted, no pages are excluded.
The location and scaling of the graphics template on the page are controlled by the optional parameters X, Y, ScaleX, ScaleY and Angle. X and Y are 0 by default, which corresponds to the lower-left corner of the page. In case the page is in landscape orientation, Angle should be set to 90 and X to the page width to properly position and orient the template.
A template is usually applied to multiple pages, and multiple templates can apply to the same page. Note that only newly added pages are subject to templating, but not existing pages. To cancel templating, the method PdfDocument.ClearTemplates should be called.
The following code snippet uses pages from existing PDF documents as templates for a new document imported from HTML. Page 1 of the new document uses head.pdf as the template, all subsequent even pages use even.pdf, and all subsequent odd pages use odd.pdf. Converting PDF pages to PdfGraphics objects is covered in Section 9.6 - Drawing Other Documents' Pages.
// Create new document
PdfDocument objDoc = objPdf.CreateDocument();
// Convert pages of existing PDFs to template graphics objects
// page 1 of Doc1
PdfDocument objDoc1 = objPdf.OpenDocument( @"c:\path\head.pdf" );
PdfGraphics objTemplate1 = objDoc.CreateGraphicsFromPage( objDoc1, 1 );
// page 1 of Doc2
PdfDocument objDoc2 = objPdf.OpenDocument(@"c:\path\even.pdf");
PdfGraphics objTemplate2 = objDoc.CreateGraphicsFromPage( objDoc2, 1 );
// page 1 of Doc3
PdfDocument objDoc3 = objPdf.OpenDocument(@"c:\path\odd.pdf");
PdfGraphics objTemplate3 = objDoc.CreateGraphicsFromPage( objDoc3, 1 );
// Set templates
objDoc.AddTemplate( objTemplate1, "From=1; To=1" ); // affect page 1 only
objDoc.AddTemplate( objTemplate2, "From=2; Exclude=1" ); // exclude odd pages
objDoc.AddTemplate( objTemplate3, "From=2; Exclude=2" ); // exclude even pages
objDoc.ImportFromUrl( "http://support.persits.com/default.asp?displayall=1" );
objDoc.Save( @"c:\path\fromhtml.pdf", false );
In case the document needs to be in landscape orientation, the code above should be modified as follows:
objDoc.AddTemplate( objTemplate1, "From=1; To=1; Angle=90; x=612" );
...
objDoc.ImportFromUrl( "http://support.persits.com/default.asp?displayall=1", "landscape=true" );
...
15.9 Support for Chinese/Japanese/Korean (CJK) Fonts
ImportFromUrl has always supported Chinese/Japanese/Korean (CJK) fonts but, unlike major browsers, required that a CJK font be explicitly specified via an HTML tag or CSS property. Otherwise, CJK characters would come out as blank squares, as on the picture below (left).
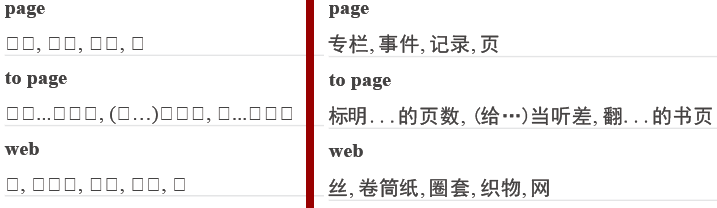
As of Version 3.4.0.3, the ImportFromUrl method is capable of automatically detecting CJK characters and displaying them using a CJK font if the current font specified by the HTML document does not support CJK glyphs. To take advantage of this feature, a CJK font has to be opened via the Doc.Fonts(...) collection or Doc.Fonts.LoadFromFile method prior to calling ImportFromUrl, and the new parameter CJK must be set to True when calling ImportFromUrl, as follows:
PdfFont objFont = objDoc.Fonts["SimHei"];
or
PdfFont objFont = objDoc.Fonts.LoadFromFile(@"c:\path\simhei.ttf");
followed by
objDoc.ImportFromUrl( url, "CJK=true; <other parameters>" );
...
The result is shown on the picture above (right). The CJK font opened prior to calling ImportFromUrl (SimHei in the example above) is the one applied to all the CJK characters that do not have their own CJK font assigned to them by the underlying HTML/CSS.

